Abstract:
The growing uses of information technology has made various financial services easily accessible to the users; nonetheless, this has also resulted in an increase in fraud transactions. Both the security of online transactions and the user experience can be improved by automatically detecting and identifying fraud. A machine learning (ML) method can be used for identifying fraud transactions. From large datasets, ML algorithms can uncover data relationships and implicit hidden patterns. Therefore, there is a possibility for identifying the outlier from each transaction with the use of such technique, which could aid in identifying fraud transaction. Support Vector Machine (SVM) and Apriori algorithm are employed in the suggested study for identifying fraud credit card transactions. The suggested system’s output is contrasted with that of another ML method currently in use. It has been found that the suggested approach had a greater accuracy rate for detecting fraud transactions as well as a lower rate of false positives for fraud transactions compared to Hidden Markov Model-based algorithm.
I. INTRODUCTION
The goal of fraud detection, a data mining (DM) classification problem, is to separate fraud transactions from authentic ones. Various banks refuse to allow academics working on fraud data classification problem for providing or fetching data because it includes private and sensitive information about individual users. Credit card fraud occurs in the case where a credit card is lost or the case where the credit card confidential credentials—which are needed to make credit card transactions—are compromised or stolen. Users can now promptly notify banks regarding missing credit cards thanks to enhanced security and banking management; as a result, different credit card fraud cases involving stolen credit card information have been reported. Therefore, banks could be notified of the compromised credit card data right away, and till fraud transactions are discovered, it is impossible to tell whether the card is compromised. Because the cardholder won’t be aware of the transactions till the credit card bill is generated, this could occasionally result in major problems [1]. The two primary categories related to credit card fraud are determined by whether the fraud transaction was conducted offline or online. Online fraud transactions are known as “fraud with on-line transaction processing,” or OLTP, since they are typically completed through using internet services [2]. Several terminals, such as retail, financial services, or customer relation management portals, are used in the execution of these OLTP frauds. Also, Point of Service (POS) transactions are completed online at retail establishments, making them a part of online payment processing methods [3]. Known as the most popular method of payment, payment gateways and POS reduce billing time. Thus, as payment gateways and internet technologies progress, so does the potential of fraud in credit card transactions. The complexity of identifying credit card frauds rises with the number of credit card transactions as well as terminals that accept credit card transactions. Therefore, it’s critical to automate the process of detecting fraud by employing computer processing or algorithms that could identify fraud transactions. ML and AI algorithms have advanced to the point that numerous medicinal [4], financial [5], and data analysis applications are using them [6]. ML-based credit card fraud detection is the subject of numerous ongoing studies [7, 8]. Since fraud transaction represents an outlier when compared to all other transactions, it can be identified through the use of ML algorithms for data analysis. The suggested system’s goal is gathering and pre-processing transaction data from a database that includes both fraud and legitimate transactions. Subsequently, a ML model generates a pattern for classifying legitimate and fraud transactions. Lastly, classify the transactions in real time with the use of classification model, and with a high level of accuracy and a low false positive rate, identify the fraud transactions. The next sections make up the structure of the suggested study. The use of credit cards and related frauds are discussed in Section I. An overview of relevant literature is provided in Section II. The suggested ML algorithm and system for identifying fraud transactions are introduced in Section III. Analysis of the suggested research’s findings using different ML algorithms is presented in Section IV. In addition, section V provides a summary of the suggested study as well as an assessment of its performance.
II. LITERATURE SURVEY
Many studies use data analysis techniques and ML algorithms for identifying fraud transactions since they are outliers compared to other transactions. Malini addresses the problem of fraudulent credit card transactions in her study [2017] [9]. In this study, different genetic algorithms, ML algorithms, and fuzzy systems are compared in terms of their ability to identify fraud credit card transactions. To enhance credit card fraud transaction detection, the outlier detection algorithm and KNN were used to the gathered data depending on data analysis and research. The study of the results demonstrates the rise in fraud transaction detection rate.
Lepovire [2016], this research used an unsupervised learning algorithm on the collected dataset for creating a fraud detection system [10]. Work packages for this study are created with the use of a classification algorithm, and after that a clustering algorithm is used to combine such packages together. Ultimately, transactions are classified as either legitimate or fraud with the use of the K-means clustering algorithm. The study of the results reveals a high rate of precision for the identification of fraud transaction.
Sumannet [2013], this research suggested a new approach for identifying fraud transactions involving telecommunication process and credit cards. To find fraud, a neural network (NN) is used to the bank transactions that have been collected. An artificial neural network (ANN) with feed backward and feed forward capabilities is made up of interconnected neurons. This aids in the clustering and classification of the collected data. The study of the research’s results demonstrates that it can identify fraud transactions faster. NNs enhance detection accuracy by supporting non-linear data modeling. In order to determine the data pattern, it can also be utilized to construct models with intricate relations between inputs and outputs [11].
Utilizing Hidden Markov model for the detection of credit cards further improves the credit card fraud detection effectiveness. Bhusari (2011) suggested a study that would enhance fraud detection by utilizing a Markov model. This study has a high frequency of fraud transaction detection and a low false positive rate. Every state in the hidden Markov model has a probability distribution attached to it, and the model is a finite set. An observation is made, depending on probability distribution of every finite set, identifying fraud transactions. The research findings indicate that the use of the Hidden Markov model improves fraud detection [12].
Bayesian network-based credit card detection improves credit card fraud detection effectiveness as well. Benson suggested a study that would employ a Bayesian network for identifying user behavior [13]. In this study, which makes use of two Bayesian networks, two assumptions are made: one regarding a legitimate user, while the other is user as a fraud. Non-fraudulent user data as well as expert knowledge are used to form a fraud net and user net in such instance. The user network is adjusted depending on real-time data. One can specify measurement probability for both the assumptions by the introduction of evidence and sending it to this network. Determining whether a behavior is legitimate or a fraud is done with the use of the distribution of probabilities.
III. PROPOSED SYSTEM
The frequent item set mining and matching algorithm are the two key components of the suggested system. The system’s goal is permitting legitimate transactions while blocking fraud ones with a lower false positive rate. To do this, a legitimate and fraud transaction group has been created via frequent item set mining, while transaction has been classified as either fraud or legitimate based on matching algorithm that matches the user’s transaction history. The system uses Apriori algorithm for frequent item set mining and SVM method for the process of matching.
Apriori Algorithm:
The present study uses Apriori classification algorithm for generating frequent item sets. It is utilized to the dataset items to refine them. Apriori algorithm’s goal is creating sets of similar items by grouping them together depending on matching attributes; these sets are referred to as frequent item sets. Also, Apriori algorithm can be defined as a bottom-up approach association rule mining method that mines the frequent itemset. The purpose of Apriori algorithm is to analyze transactional databases. The Apriori algorithm takes a value of threshold ε as input and creates a frequent itemset, which are subsets of all transactions that contain at least ε. A common subset is expanded through adding one item at a time with the use of bottom-up technique [14]. We refer to this phase as the “candidate generation step.” The procedure continues iterating till a termination candidate arises, at which point there is no more room for extending the itemset. The Apriori algorithm uses confidence and support values to produce a frequent itemset. Support can be defined as a representation of transactions that include multiple products in a single transaction. When items are similar, transactions are represented by confidence. Items having greater confidence and support values compared to the threshold are found in a frequent item set. For two itemsets Q and P, confidence and support could be computed as follows:
There are two steps in the apriori algorithm:
Step1: Find all of the frequent itemset from data-base.
Step2: Creating association rule from the frequent itemset that has been generated in step1.
- Pseudo Code Sets:
F: represents Frequent itemset of size n
C: represents a candidate set of size n
- Join Step:
Ck is produced from the joining of Fk-1 with itself.
- Prune Step:
Itemset which isn’t frequent can’t be sub-set Frequent itemset.
- Pseudo Code:
F1 represents frequent itemset
For n=1 and frequent itemset isn’t null, increment k
Ck represents the Candidate set that has been generated from F1
For each Transaction t in the data-base
Increment count of all of the candidates that belong to Cn+1 and in t
Fn+1 = Candidate with support greater than threshold and belong to Cn+1
End
Return Fn
SVMs:
SVMs are supervised learning algorithms related to regression and classification. The SVM’s hyperplane classifies several classes according to their differences and similarities. A hyperplane used in the suggested study distinguishes between credit card transactions that are fraud and those that are legitimate. A hyperplane that correctly classifies two classes with a larger margin is thought to be more accurate. For dividing a given set of data into at least two classes, SVMs have hyperplanes [15]. Credit card transaction data is classified based on hyperplane’s maximal width.
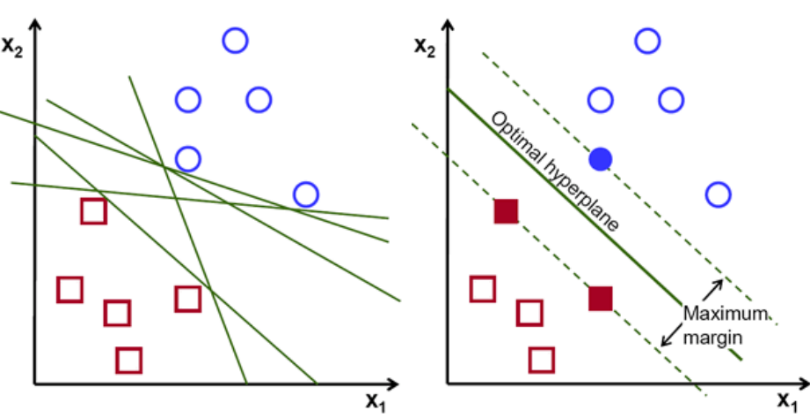
Figure1: Support Vector Machines
SVMs working principle is depicted in Figure 1. A line that splits the data is known as optimal hyperplane. The optimal hyperplane or decision boundary is found using the other two lines shown in the figure. A margin is the separation between two hyperplanes. All data points should be distinct from the boundary when choosing a margin; these points are referred to as support vectors. New credit card transactions are checked for fraud with the use of trained model.
Proposed System:
The matching algorithm and frequent item set mining are the two key components of the suggested system. To do this, legitimate and fraud transaction group is created via frequent itemset mining, while transaction has been classified as either legitimate or fraud based on the matching algorithm that matches user’s transaction history. The system uses Apriori algorithm for the frequent itemset mining and SVM method for matching. The suggested system’s process is depicted in Figure 2.
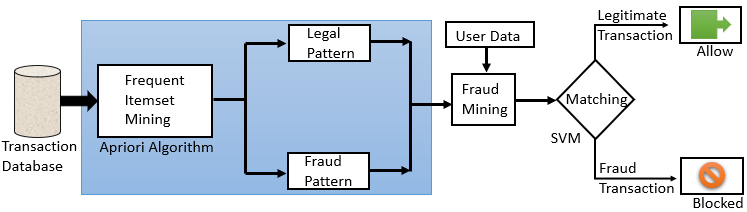
Figure 2: Workflow of the suggested system
A set of transactions has been gathered from the data-set, as seen from figure 2. Transactions are represented by a row in this example, and attributes are represented by columns. After that, a frequent itemset mining procedure is carried out with the use of Apriori algorithm for identifying frequent itemset in credit card transactions. Items are classified into legitimate and fraud patterns with the use of frequent item set mining, and a transaction count is produced for each one of the patterns. Total user-specific transactions could be analyzed using count. Two groups—legal transaction pattern and fraud transaction pattern—are produced depending on the user’s prior transactions. After that, it groups users’ transactions through employing bank account numbers to analyze each user’s transaction. The previously established legal and fraud group is used to validate new transaction data whenever the user attempts to complete a new transaction. A prediction is made throughout matching using the new transaction as well as the ML model. This prediction is used to classify the transaction as fraud or legitimate. In the event that a transaction is flagged as fraud, the system blocks it, notifies the use and administrator, and allows the transaction to proceed in the case of legitimate transaction.
IV. RESULT ANALYSIS
The suggested work is subjected to an experimental investigation with the use of the UCI ML Repository. Transaction data related to credit cards is taken from such repository. Transaction data that has been verified is contained in UCI ML Repository. There are 10,000 transactions with 23 attributes in the data. The transaction includes information about the total credit amount, the account holder’s gender, age, marital status, and education. It also includes six attributes that include the account holder’s credit history for the previous six months, other repayment information, bill statements, and defaulter history for that particular month. This data is utilized for testing and training the suggested model in order to assess the system’s performance. Accuracy, f-score, and precision of several algorithms are compared in order to analyze the outcome of the suggested method with an existing ML algorithm. The comparison between the suggested algorithm and the current ML algorithm is displayed in Table 1.
| Algorithm | Data-set | Precision | Recall | F-measure | Accuracy |
| Random forest classifier | 10,000 | 79.980% | 88.230% | 82.100% | 84.320% |
| K-means Clustering | 10,000 | 73.780% | 83.450% | 77.250% | 78.340% |
| Hidden Markov model | 10,000 | 84.670% | 93.110% | 87.980% | 89.430% |
| Proposed Algorithm | 10,000 | 89.550% | 96.570% | 92.330% | 94.560% |
Table 1: Comparison of the suggested algorithm against the existing ML algorithm
Table1 presents a comparison regarding the suggested method with the present algorithm. It can be noticed that the accuracy of suggested algorithm is higher compared to that of existing algorithm, and there is improvement in other metrics such as recall, precision, and F-measure. This investigation analysed a total of 10,000 transactions, finding that 9456 of them were successfully identified. This demonstrates that the proposed algorithm can identify fraud transactions in real time.
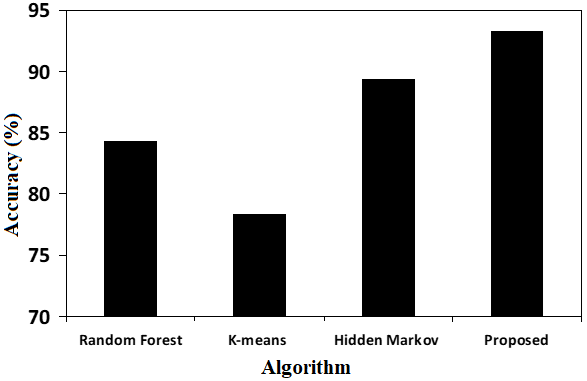
Chart 1: Accuracy Comparison
The suggested approach outperforms K-means, random forest (RF), and hidden Markov model in terms of accuracy, as demonstrated by Chart 1. But when it comes to credit card truncation, accuracy is just as crucial as the algorithm’s false positive rate. The credit card users or administrator will become irritated if there are several false triggers for fraud transactions, which could lead to ignorance about fraud changes. The test results of various ML algorithms are put to comparison with the suggested approach in order to ascertain the ratio of false transactions. Through taking into account the total number of fraud transactions that have been discovered and the number of false fraud transactions, Chart 2 compares the suggested algorithm with RF, hidden Markov model, and K-means.
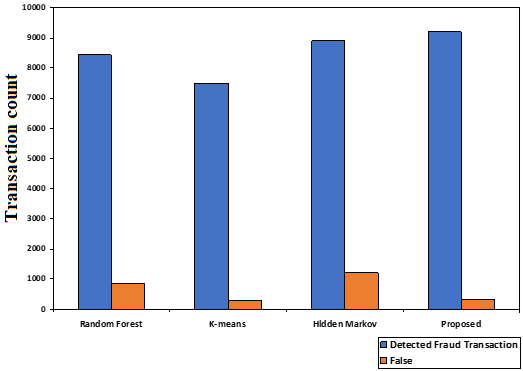
Chart 2: Comparison of the False Fraud detection
Chart 2 demonstrates that while fraud detection in Hidden Markov model and RF is higher, it frequently results in false fraud transactions, which could negatively impact user experience and system performance. In contrast, K-means algorithm is observed to have a lower false fraud detection rate, yet it fails to identify true fraud transactions, which will decrease system accuracy. However, it is noted that the suggested method has a high accuracy in detecting fraud transactions and generates fewer false triggers for fraud transactions.
Comparisons of Time complexity:
Regarding credit card fraud detection, time complexity is just as crucial as false trigger rate and accuracy. Because using cloud takes more time or requires more effort, users may find alternative ways to pay and have a worse user experience. The suggested technique is compared with RF, hidden Markov model, and K-means with variable transaction count in Chart 3.
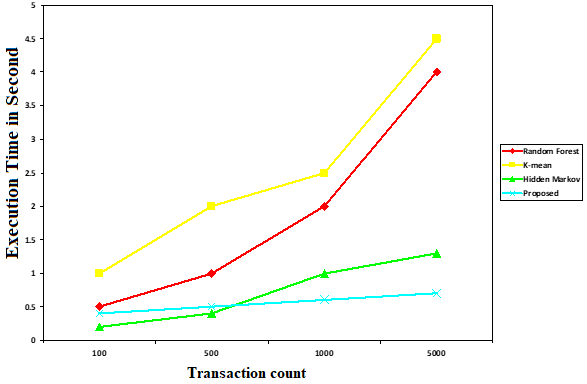
Chart 3: Comparison of Time complexity
The suggested technique is compared with K-means, RF, hidden Markov model with variable transaction count in Chart 3. When pu to comparison with RF, hidden Markov, and K-means models, the time complexity regarding the suggested algorithm is extremely comparable for transaction counts under 100. Yet, when transaction counts rise, the time complexity related to other algorithms decreases sharply, while in the suggested algorithm, complexity has been maintained and increases just a little bit. This suggests that the suggested algorithm’s time complexity is superior for both large and small transaction counts. According to the results of the examination of charts 1, 2, and 3, the suggested algorithm, when put to comparison with the current systems, generates fraud transaction results with high accuracy, an increased time complexity, and lower false positive rate.
V. CONCLUSION
The proposed system aims at gathering transactions from a data-base that include both fraud and legitimate transactions. Subsequently, a ML model generates a pattern for classifying legitimate and fraud transactions. Lastly, classify the transactions in real time with the use of classification model, and with a high degree of accuracy and a low rate of false positive cases, identify fraud transactions. The frequent item set mining as well as matching algorithm are the two key components of the suggested system. A fraud and legitimate transaction group is created by frequent mining item sets. A matching algorithm is then used to match user-specific transaction histories, classifying the transaction as either fraud or legitimate. The system uses the Apriori algorithm for frequent item set mining and SVM for matching. Accuracy, f-score, and precision of several algorithms are put to comparison in order to analyze the outcome of the suggested method with an existing ML algorithm. According to the results of the investigation, the suggested method outperforms the current approach in terms of accuracy. It performs better when measured in terms of recall, precision, and F-measure. The test results of various ML algorithms are put to comparison with the suggested approach in order to ascertain the ratio of false transactions. It has been noted that the suggested algorithm has a high accuracy rate for detecting fraud and generates fewer false positives for fraud transactions. With regard to credit card fraud detection, time complexity is just as crucial as false trigger rate and accuracy. When put to comparison with other algorithms, the time complexity regarding the suggested algorithm is found to be extremely comparable for transaction counts under 100. Yet, when transaction counts rise, the time complexity regarding other algorithms decreases noticeably, while the complexity of the suggested algorithm remains constant. This demonstrates how the suggested approach improves false positive rate, accuracy, and time complexity. Features like less reliance on the system for the detection of fraud transactions, a lower likelihood of false alarm triggers, and a quicker time for the fraud transaction detection are provided by this.
REFERENCES
[1] Review on fraud detection methods in credit card transactions, Krishna Modi; Reshma Dayma, DOI: 10.1109/I2C2.2017.8321781, International Conference on Intelligent Computing and Control (I2C2), Coimbatore, India, 2017
[2] Online Transaction Fraud Detection System, I. Mettildha Mary; M. Priyadharsini;Karuppasamy. K; Margret Sharmila. F, DOI: 10.1109/ICACITE51222.2021.9404750,, International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 2021
[3] Fraud Detection and Prevention by using Big Data Analytics, Bineet Kumar Jha G G Sivasankari;K R Venugopal, Fourth International Conference on Computing Methodologies and Communication (ICCMC), DOI: 10.1109/ICCMC48092.2020.ICCMC-00050, Erode, India, 2020
[4] Short and long term stock trend prediction using decision tree, Rupesh A. Kamble, International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, DOI: 10.1109/ICCONS.2017.8250694, 2017
[5] Data Pre-processing and Apriori Algorithm Improvement in Medical Data Mining, Feng Lv, 6th International Conference on Communication and Electronics Systems (ICCES), India, DOI: 10.1109/ICCES51350.2021.9489242, 2021
[6] Analysis of University Students Employment Recommendation System Based on Apriori Algorithm, Hao Wu;Qian Liu;Zhifang Zhang, Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), China, DOI: 10.1109/IPEC49694.2020.9115188, 2020
[7] Supervised Machine Learning Algorithms for Credit Card Fraud Detection: A Comparison, Samidha Khatri, Aishwarya Arora; Arun Prakash Agrawal, 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), DOI: 10.1109/Confluence47617.2020.9057851, India, 2020
[8] A Novel Approach for Credit Card Fraud Detection using Decision Tree and Random Forest Algorithms, M R Dileep A V Navaneeth M Abhishek, Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), India, DOI: 10.1109/ICICV50876.2021.9388431, 2021
[9] Investigation of Credit Card Fraud Recognition Techniques based on KNN and HMM, N. MaliniM. Pushpa, IJCA Proceedings on International Conference on Communication, Computing and Information Technology, 2017
[10] Credit Card Fraud Detection with Unsupervised Algorithms, Maria R. Lepoivre, Chloé O. Avanzini, Guillaume Bignon, Loïc Legendre, and Aristide K. Piwele, Journal of Advances in Information Technology Vol. 7, No. 1, February 2016.
[11] Suman, Nutan, “Review Paper on Credit Card Fraud Detection”, International Journal of Computer Trends and Technology (IJCTT) – volume 4 Issue 7–July 2013.
[12] V. Bhusari S. Patil, “Study of Hidden Markov Model in Credit Card Fraudulent Detection”, International Journal of Computer Applications (0975 – 8887) Volume 20– No.5, April 2011
[13] Analysis on credit card fraud detection methods, Benson Edwin Raj, A. Annie Portia, DOI:10.1109/ICCCET.2011.5762457, Computer, Communication and Electrical Technology (ICCCET), 2011 International Conference on, 2011
[14] Research and improvement of Apriori algorithm, Jiaoling Du;Xiangli Zhang;Hongmei Zhang;Lei Chen, Sixth International Conference on Information Science and Technology (ICIST), Dalian, China, DOI: 10.1109/ICIST.2016.7483396, 2016
[15] Relative Analysis of ML Algorithm QDA, LR and SVM for Credit Card Fraud Detection Dataset, P Naveen;B Diwan, Fourth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), 2020
Cite This Work
To export a reference to this article please select a referencing stye below:

Academic Master Education Team is a group of academic editors and subject specialists responsible for producing structured, research-backed essays across multiple disciplines. Each article is developed following Academic Master’s Editorial Policy and supported by credible academic references. The team ensures clarity, citation accuracy, and adherence to ethical academic writing standards
Content reviewed under Academic Master Editorial Policy.


